One thing that has always struck me as surprising is the large number of homophones – words with the same pronunciation – in the Japanese language. Those new to Japanese typically discover this by looking at the number of dictionary entries for a given pronunciation, or number of kanji conversions when hitting spacebar while typing.
In the spoken world, pitch accent (discussed here) helps to distinguish these, but there are many regional variations and some words can be pronounced with more than one pitch pattern. In the written world, things are made manageable by kanji which differentiates the meaning, like 橋 (bridge) vs 箸 (chopsticks), which are both pronounced as “hashi”. In this example the pitch accent is different, but for non-natives it can be very hard to distinguish that. Some people have also claimed that one of the reasons subtitles are so common certain types of Japanese TV is that it helps differentiate the meaning of certain words which have homonyms, though I don’t think this is the only reason.
One thing that always caught my interest was exactly how frequent these homonyms really are. Are they actually more frequent that in English, or is it just that I can naturally differentiate those in my native language so I don’t realize them as much?
I stumbled upon Jim Breen’s EDICT, which is a freely available file containing around 170,000 entries of Japanese words with their readings and meanings. This gave me the idea that with a little scripting this file could be data mined for exactly what I was looking for – the frequency of homophones in Japanese.
In my analysis, I generated both a histogram of the number of homonyms, as well as a list of the pronunciations with the highest number of homonyms.
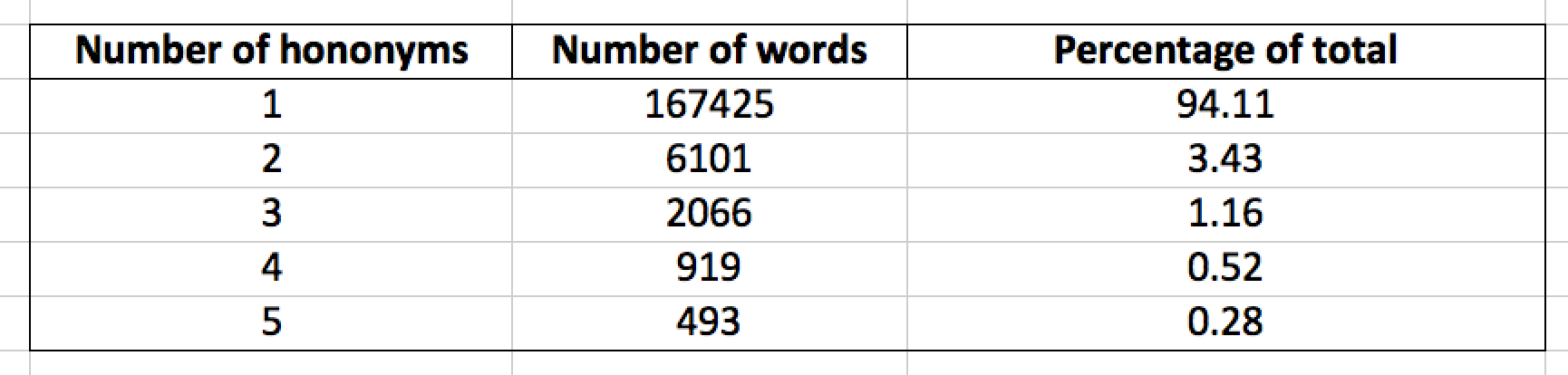
Histogram of homonym frequency (excerpt)
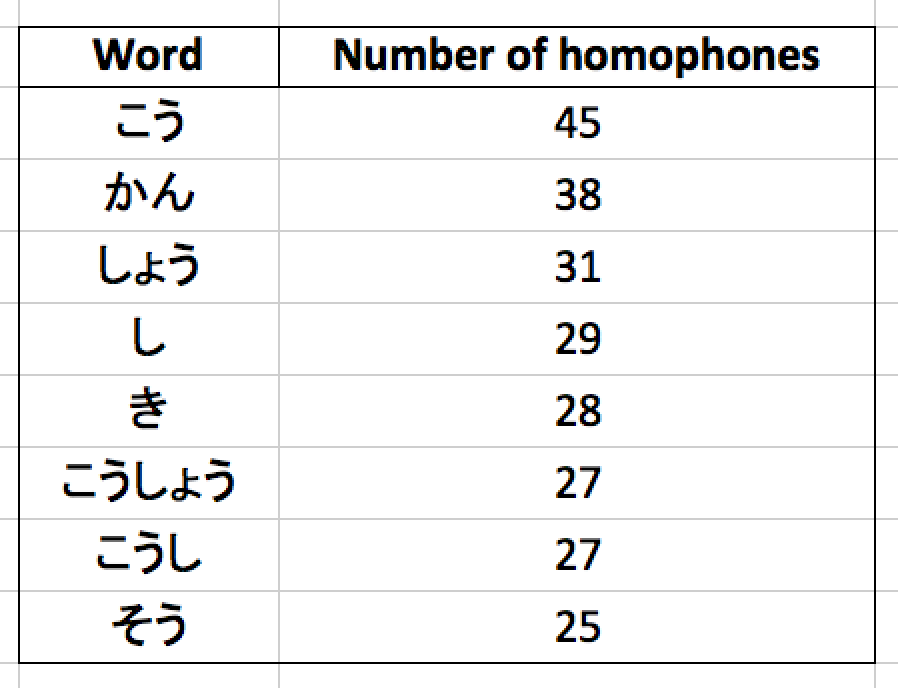
Words with highest number of homonyms (excerpt)
Note: In both graphs, I have only showed a few data points. If anyone is interested in the rest of the details let me know and I can try to prepare a more detailed report.
Analysis
From the first graph, we can see that roughly 94% of all words in Japanese do not have a homophone, which is significantly less than I expected. There are around 3% (~6000) words which have one homophone and 1% (~2000) which have two. The curve goes down fast and there are only a total of 55 words (0.03% of total) which have 10 homophones.
Though there are only a few words in Japanese which have a large number of homophones, it you look at the second graph above you’ll see that most of those are short and contain sounds which are commonly used in Japanese. “こう” is the winner for the most homophones, with a whopping 45! “かん” and “しょう” have 38 and 31, respectively.
The good news, which this data doesn’t really capture, is that many of the homophones are not frequent in Japanese, especially everyday conversation. More advanced topics like science, government, and academic subjects tend to use more of these homophones, and if you include older words when are no longer in common use you get more still. Fortunately, more homophones tend to be used in Japanese writing (on advanced topics), but the kanji there helps make up for it.
Although this little exercise did temporarily quench my research thirst about homophones in Japanese, there is still much more work to be done in this area. Firstly, a similar sort of analysis needs to be done to English and only then can we compare these two languages on (semi) equal ground. To get even more meaningful results, the word frequency in modern language would need to be factored into use, filtering out those homophones which are never or almost never used in practice. This might be able to be done using some targeted Google searches (hopefully in a programmatic way with available public APIs), but that would take a good bit of time.
References
http://www.edrdg.org/jmdict/edict.html
Hello,
I have been enjoying reading your blog (I am following your Twitter as well). I am interested in the number of homonyms (as well as the frequency of the words), so I’ve downloaded the Jim Breen’s EDICT data, but I have no idea how to extract the information from the kind of data, since I am novice in scripting (I use R for data analysis and I do a very basic scripting in Praat). Would you tell me (email me) how you wrote the script to extract the information? I have another data that is similar to the Jim Breen’s EDICT data but not sure how to extract the frequency information from the data either.
Thank you very much
Hi Yoichi. Thanks for the comment and glad you are enjoying my blog. I wrote this article a few years ago and haven’t been able to find the script I wrote, but I remember it was pretty straightforward.
I know a few programing languages (C/C++/Perj/Java/Objective C) and doing this kind of analysis would be pretty easy, but I can’t say much about R or Praat.
However, conceptually you have to do the following:
1) Parse each line to get at the data you want. I don’t remember the data format, but if for example it was “AAA;BBB;CCC;DDD” and “CCC” was the word, then you would have to split on a semicolon, and find the “CCC” part.
2) Put the CCC into some sort of dictionary structure, where you count the number of instances. This is pretty easy in any modern day, full-featured programming language.
3) Once you are done going through the file, you need to sort the dictionary using the counts for each element, or keep it sorted while you are creating it.
Let me know if you need any more help.
Thank you for your reply, locksleyu
I will try it out and let’s see how it work!
Interesting research. Would be interested to see the results with proper names such as names of places and people included. I guess that the proportion of homophones will be much higher.
I’m no expert in the matter, but I think Japanese suffers from an extremely high number of homophobes because the language has been inconviniently and unnecessarily sinified by the upper clases since ancient times without the natural filtering that is the common people. Take a look at word like 新車 for “new car”. Why does Japanese need to have a specific concept for new car when it can perfectly say 新しい車? It doesn’t. The words exist in Japanese. There is no need to conceptualise the idea as if Japanese were Chinese. Chinese say 新車 because that how the language works, they can easily distinguish each character or word. When you try to make Japanese work like Chinese you end up creating a large amount of homophobes that you can hardly disambiguate because Japanese doesn’t have the phonetic qualities of Chinese. Homophobes with more than 10 or 15 meanings. That’s simply crazy and inconvinient.